











 Inglés (pdf)
Inglés (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo

 Permalink
Permalink
Introduction
Computational thinking (CT) is becoming a fundamental skill for 21st-century citizens worldwide (Grover & Pea, 2018; Nordby et al., 2022) since it is related to beneficial skills that are considered applicable in everyday life (Wing, 2006; 2017). Algorithmic thinking (AT) is considered the main component of CT (Juškevičienė, 2020; Selby & Woollard, 2013; Stephens & Kadijevich, 2020). Moreover, most of the CT definitions have their roots in AT (Juškevičienė, 2020), although some very influential CT definitions do not mention AT at all (Shute et al., 2017; Weintrop et al., 2016; Wing, 2006).
Today, daily life is surrounded by algorithms and governed by algorithms, so AT is considered one of the key elements to be an individual aligned with the era of computing (Juškevičienė, 2020). Research on AT is very important in computer science education, but it also has a vital role in mathematics education and STEAM contexts (Kadijevich et al., 2023). Despite its importance, AT has been found to lack research that treats it as an independent construct with independent-of-CT assessments (Park & Jun, 2023).
CT is still a blurry psychological construct, and its assessment remains a thorny, unresolved issue (Bubica & Boljat, 2021; Martins-Pacheco et al., 2020; Román-González et al., 2019; Tang et al., 2020), and open, as a research challenge, demanding scholars’ attention urgently (Poulakis & Politis, 2021). Moreover, the same happens with AT (Lafuente Martínez et al., 2022; Stephens & Kadijevich, 2020) due to its relationship with CT.
A wide variety of CT assessment tools are available (Tang et al., 2020; Zúñiga Muñoz et al., 2023), ranging from diagnostic tools to measures of CT proficiency and assessments of perceptions and attitudes towards this thinking way, among others. (Román-González et al., 2019). However, empirical research evaluating the validity and reliability of these instruments remains relatively low compared to the volume of research in this area (Tang et al., 2020). Consequently, as noted by Bubica and Boljat (2021), “there is still not enough research on CT evaluation to provide teachers with enough support in the field” (p. 453).
While much research focuses on measuring and assessing CT (Poulakis & Politis, 2021), the same cannot be said for AT. Moreover, these research streams do not converge (Stephens & Kadijevich, 2020). Furthermore, a limited percentage of research on CT assessment is directed towards undergraduate students (Tang et al., 2020).
A limited number of efforts, albeit divergent, have been made to formulate operational definitions for AT, as evidenced by works such as those by Juškevičienė and Dagienė (2018), Lafuente Martínez et al. (2022), Navas-López (2021), and Park and Jun (2023). Additionally, attempts have been undertaken to develop an assessment rubric (Navas-López, 2021) and apply confirmatory factor analysis (CFA) for AT measurement instruments (Bubica & Boljat, 2021; Lafuente Martínez et al., 2022).
Despite these contributions, there remains a notable gap in the literature regarding validating instruments specifically designed to assess AT as an independent construct distinct from CT. So far, there are only two factorial models for AT in adolescents or adults with acceptable psychometric properties: a unifactorial model (Lafuente Martínez et al., 2022) and a bifactorial model (Ortega Ruipérez et al., 2021). Therefore, this research endeavors to develop a more detailed factorial model through the construct validation of the rubrics applied by Navas-López (2021) to assess AT in undergraduate students.
Developing reliable instruments for studying AT is crucial, particularly with the rising integration of CT and AT in basic education curricula around the world (Kadijevich et al., 2023). Continuous research is crucial to identify components, dimensions, and factors that illuminate the assessment of AT (Lafuente Martínez et al., 2022; Park & Jun, 2023).
Literature review
Some definitions
As this paper focuses on AT, it is crucial to understand the concept of an algorithm clearly. According to Knuth (1974), an algorithm is defined as "a precisely-defined sequence of rules instructing how to generate specified output information from given input information within a finite number of steps" (p. 323). This definition encompasses human and machine execution without specifying any particular technology requirement.
In line with this definition, Lockwood et al. (2016) describe AT as “a logical, organized way of thinking used to break down a complicated goal into a series of (ordered) steps using available tools” (p. 1591). This definition of AT, like the previous definition of algorithm, does not require the intervention of any specific technology.
For Futschek (2006), AT is the following set of skills that are connected to the construction and understanding of algorithms:
a. the ability to analyze given problems,
b. the ability to specify a problem precisely,
c. the ability to find the basic actions that are adequate to the given problem,
d. the ability to construct a correct algorithm for a given problem using the basic actions,
e. the ability to think about all possible special and regular cases of a problem,
f. the ability to improve the efficiency of an algorithm. (p. 160)
There are other operational definitions for AT. Some of them emphasize specific skills, such as the correct implementation of branching and iteration structures (Grover, 2017; Bubica & Boljat, 2021). Most of them describe AT in terms of a list of skills (Bubica & Boljat, 2021; Lafuente Martínez et al., 2022; Lehmann, 2023; Park & Jun, 2023; Stephens & Kadijevich, 2020), such as analyzing algorithms or creating sequences of steps. Despite similarities, these skill lists cannot be considered equivalent to each other.
The definition of CT will now be addressed by expanding on the concept of AT. It could be defined as “the thought processes involved in formulating a problem and expressing its solution(s) in such a way that a computer -human or machine- can effectively carry out” (Wing, 2017, p. 8). Unlike the AT definitions, this CT definition allows for machines' involvement. Consequently, CT does involve considerations about the technology underlying the execution of these solutions (Navas-López, 2024).
As with AT, different operational definitions of CT describe it as a list of various components or skills, such as abstraction, decomposition, and generalization (Otero Avila et al., 2019; Tsai et al., 2022). Additionally, several authors explicitly include AT as an operational component of CT in their empirical research (Bubica & Boljat, 2021; Korkmaz et al., 2017; Lafuente Martínez et al., 2022; Otero Avila et al., 2019; Tsai et al., 2022).
For Stephens and Kadijevich (2020), the cornerstones of AT are decomposition, abstraction, and algorithmization, whereas CT incorporates these elements along with automation. This distinction underscores that automation is the defining factor separating AT from CT.
Lehmann (2023) describes algorithmization as the ability to design a set of ordered steps to produce a solution or achieve a goal. These steps include inputs and outputs, basic actions, or algorithmic concepts such as iterations, loops, and variables. Note the similarity with Lockwood et al. (2016) definition of AT.
Kadijevich et al. (2023) assert that AT requires distinct cognitive skills, including abstraction and decomposition. Following Juškevičienė and Dagienė (2018), decomposition involves breaking down a problem into parts (sub-problems) that are easier to manage, while abstraction entails identifying essential elements of a problem or process, which involves suppressing details and making general statements summarizing particular examples. Furthermore, these two skills are present in many CT operational definitions (Bubica & Boljat, 2021; Juškevičienė & Dagienė, 2018; Lafuente Martínez et al., 2022; Martins-Pacheco et al., 2020; Otero Avila et al., 2019; Selby & Woollard, 2013; Shute et al., 2017).
Unsurprisingly, the most commonly assessed CT components are algorithms, abstraction, and decomposition (Martins-Pacheco et al., 2020), which closely aligns with the AT conception by Stephens and Kadijevich (2020). In fact, in the study conducted by Lafuente Martínez et al. (2022), the researchers aimed to validate a test for assessing CT in adults, avoiding technology (or automation). However, their CFA results suggest a simpler CT concept, governed by a single ability associated with recognizing and expressing routines to address problems or tasks, akin to systematic, step-by-step instructions-essentially, AT.
The distinction between AT and CT remains to be clarified in current scientific literature. Nonetheless, this study adopts Stephens and Kadijevich's (2020) perspective, emphasizing that the primary difference lies in automation. Specifically, AT excludes broader aspects of technology use and social implications (Navas-López, 2024). The study also focuses on abstraction and decomposition as integral components of AT.
Algorithmic thinking and Computational thinking assessments
According to Bubica and Boljat (2021), “to evaluate CT, it is necessary to find evidence of a deeper understanding of a CT-relevant problem solved by a pupil, that is, to find evidence of understanding how the pupil created their coded solution” (p. 428). Grover (2017) recommends the use of open-ended questions for making “systems of assessments” to assess AT.
Bacelo and Gómez-Chacón (2023) emphasize the significance of unplugged activities for observing students' skills and behaviors, and identifying patterns that can reveal strengths and weaknesses in AT learning, as shown by Lehmann (2023). Empirical data suggests that students engaged in unplugged activities demonstrate marked improvements in CT skills compared to those in plugged activities (Kirçali & Özdener, 2023). Unplugged activities are generally effective in fostering CT skills (Chen et al., 2023), making them essential components in AT assessment instruments to identify patterns that reveal strengths and weaknesses.
There is a common tendency to assess AT and CT through small problem-solving tasks, often using binary criteria like 'solved/unsolved' or 'correct/incorrect' without detailed rubrics for each problem. Examples can be found across different age groups: young children (Kanaki & Kalogiannakis, 2022), K-12 education (Oomori et al., 2019; Ortega et al., 2021), and adults (Lafuente Martínez et al., 2022). Conversely, there are proposals to qualitatively assess CT using unplugged complex problems, focusing on students' cognitive processes (Lehmann, 2023).
In addition, Bubica and Boljat (2021) suggest adapting problem difficulty to students' level, because assessments for AT and CT vary in effectiveness for different learners (Grover, 2017). Therefore, an effective AT assessment should include unplugged, preferably open-ended problems adjusted to students' expected levels to identify cognitive processes better.
Validity of CT/AT instruments through factor analysis
According to Lafuente Martínez et al. (2022), assessments designed to measure CT in adults, as discussed in the literature, often lack substantiated evidence concerning crucial validity aspects, particularly the internal structure and test content. Some studies validate CT instruments, which include the AT construct, through factor analysis, but they have problems with psychometric properties, such as those of Ortega Ruipérez and Asensio Brouard (2021), Bubica and Boljat (2021) and Sung (2022).
Ortega Ruipérez and Asensio Brouard (2021) shift the focus of CT assessment towards problem-solving to measure the performance of cognitive processes, moving away from computer programming and software design. Their research aims to validate an instrument for assessing CT through problem-solving in students aged 14-16 using CFA. However, the instrument exhibits low factor loadings, including one negative. By emphasizing problem-solving outside the realm of computer programming, this instrument aligns more closely with the interpretation of AT by Stephens and Kadijevich (2020), as it removes automation from CT. Nevertheless, its results are pretty poor, as the conducted CFA only identifies two independent factors: problem representation and problem-solving.
Bubica and Boljat (2021) applied an exploratory factor analysis for a CT instrument, special for the Croatian basic education curriculum, with a mix of simple answer questions and open-ended problems in students aged 11-12. AT evaluation criteria focus on sequencing, conditionals, and cycles. However, the factor loadings are low, and the grouping of the tasks (items) according to the factor analysis is strangely overloaded towards one factor.
Sung (2022) conducted a validation through CFA for two measurements to assess CT in young children aged 5 and 6 years. It has certain limitations, including the weak factor loadings of specific items, suboptimal internal consistency in subfactors, and low internal reliability. Furthermore, Sung (2022) reflects that “young children who are still cognitively developing and lack specific high-level thinking skills seem to be at a stage before CT’s major higher-order thinking functions are subdivided” (p. 12992). This may be the same problem in Bubica and Boljat’s (2021) study results.
Lafuente Martínez et al. (2022) performed a CFA for a CT instrument for adults (average 23.58 years), and they did not find multidimensionality in their evidence, thus failing to confirm the assumption of difference between CT and AT.
Other CFA studies focus on CT instruments with strong psychometric properties, but they primarily assess disposition toward CT rather than problem-solving abilities. For instance, Tsai et al. (2022) used CFA to validate their 19-item questionnaire, demonstrating good item reliability, internal consistency, and construct validity in measuring CT disposition. Their developmental model highlighted that decomposition and abstraction are key predictors of AT, evaluation, and generalization, suggesting their critical role in CT development.
So, there is a lack of CFA-specialized studies on AT published in the last five years, independent of CT, focused solely on problem solving, and on university/college undergraduate students (young adults).
Rubric for algorithmic thinking
According to Bubica and Boljat (2021), algorithmic solutions are always difficult to evaluate because “in the process of creating a model of evidence, it is crucial to explore all possible evidence of a pupil’s knowledge without losing sight of the different ways in which it could be expressed within the context and the requirements of the task itself” (p. 442). Therefore, one way to assess students’ performance objectively and methodically is through a rubric (Chowdhury, 2019).
Furthermore, it is highly recommended to construct rubrics to assess students’ learning, cognitive development, or skills, based on Bloom’s taxonomy of educational objectives (Moreira Gois et al., 2023; Noor et al., 2023). This taxonomy of educational objectives includes Knowledge (knowing), understanding, application, analysis, synthesis, and evaluation (Bloom & Krathwohl, 1956).
Although some more or less precise recent operational definitions have been proposed for AT (Juškevičienė & Dagienė, 2018; Lafuente Martínez et al., 2022; Park & Jun, 2023), these do not include a specific (or general) rubric to assess performance levels for each of the components or factors these operational definitions claim to compose the AT construct.
The only rubric to measure AT development found, independent of CT, based on open-ended problem solving for undergraduate students, is that by Navas-López’s (2021) master thesis. This study has a correlational scope and does not include construct validation for the rubric.
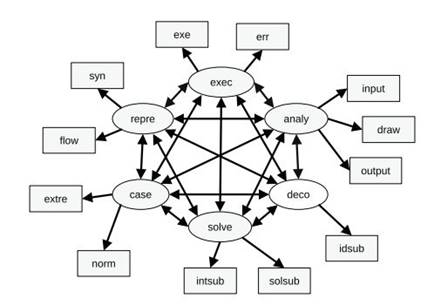
Navas-López (2021) proposed two operationalizations for AT: One operationalization is for a beginner’s AT level, and the other is for an expert’s AT level. In the skills list that composes a beginner’s AT, the educational objectives of Knowledge (knowing), understanding and application (execution) of algorithms have been included. Table 1 shows the latent variables (components or factors) and observable variables of the operationalization for a beginner’s AT, according to this proposal, and Figure 1 shows the corresponding structural model.
Table 1: Generic operationalization of a beginner’s algorithmic thinking
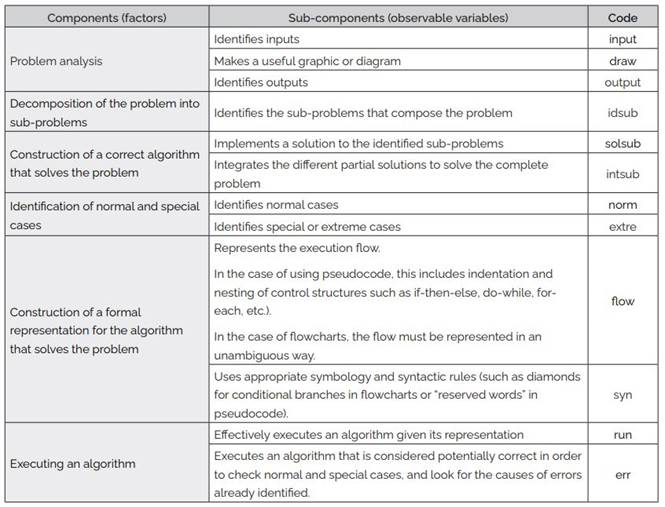
Note. Translation of Table 3.3 from Navas-López (2021, p. 60)
Navas-López (2021) explains that he primarily used the definition provided by Futschek (2006) due to its wide referencing in multiple publications on AT and CT. However, he supplemented his operational definition with the definition by Grozdev and Terzieva (2015), particularly concerning problem decomposition, the relationship between sub-problems, and the formalization of algorithm representation. Finally, the notion of algorithm debugging from Sadykova and Usolzev (2018) was incorporated.
This proposal also incorporates the components outlined by Stephens and Kadijevich (2020): Abstraction in problem analysis and identification of sub-problems, decomposition explicitly, and algorithmization, as understood by Lehmann (2023).
Navas-López (2021) also developed a generic analytic rubric to assess a beginner’s AT level from its factors for a given problem, following the steps of Mertler’s (2001) scoring rubric design and the template presented by Cebrián de la Serna and Monedero Moya (2014). Table 2 shows the detailed rubric.
Table 2: Generic analytic rubric to assess a beginner’s algorithmic thinking level
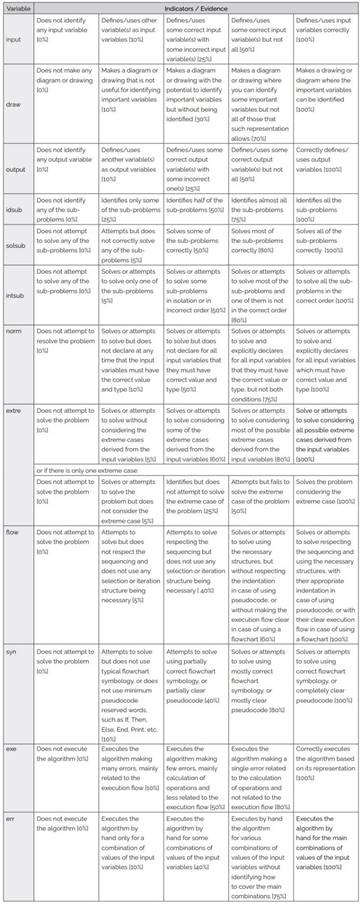
Note. Translation of Table 3.4 from Navas-López (2021, pp. 61-65)
Navas-López (2021) also developed two specific rubrics for the two problems, the solution of which is an algorithm contained in the instrument used (p2 and p4). These two rubrics are versions derived from the one presented in Table 2 but adjusted to the particularities of both problems. Besides, both problems do not include the execution of the resulting algorithm due to time restrictions during the administration of the instrument, so they do not consider the component "Executing an algorithm" (from Table 1), that is, the exe and err variables. One of the problems did not require a graphic or diagram to be analyzed and solved, so it does not include the draw variable. So, observable variables assessed for problem p2 are: p2. input, p2.output, p2.idsub, p2.solsub, p2.intsub, p2.norm, p2.extre, p2.flow, p2.syn; and for problem p4 are: p4.input, p4.draw, p4.output, p4.idsub, p4.solsub, p4.intsub, p4.norm, p4.extre, p4.flow, p4.syn.
This research aims to construct validation for the specific rubrics applied by Navas-López (2021) as part of his operational definition for assessing AT in undergraduate students. Specifically, this construct validation will be carried out through CFA applied to several models proposed by the researcher based on the grouping of the measured variables for the two problems in the original measurement instrument.
Method
Problems p2 and p4, extracted from the instrument developed by Navas-López (2021), were administered to a sample of 88 undergraduate students enrolled in three academic programs offered by the School of Mathematics at the University of El Salvador. The participants, aged 17 to 33 (M: 20.88 years, SD: 2.509 years), included 41 women (46.59%), 46 men (52.27%), and 1 participant who did not report their gender. The overall grades of the subjects ranged from 6.70 to 9.43 on a scale of 0.00 to 10.00 (M: 7.64, SD: 0.57). The total student population at the time of data collection was 256, and a convenience sampling approach was employed during regular face-to-face class sessions across different academic years (first year, second year, and third year). The researcher verbally communicated the instructions for solving the problems, after which students individually solved them on paper, with the option to ask questions for clarification.
The translation of Navas-López’s (2021) problem p2 is:
A school serving students from seventh to ninth grade organizes a trip every two months, including visits to a museum and a theater performance. The school principal has established a rule that one responsible adult must accompany every 15 students for each trip. Additionally, it is mandated that each trip be organized by a different teacher, with rotating responsibilities. Consequently, each teacher may go several months (or even years) without organizing a trip, and when it is their turn again, they may not remember the steps to follow. Develop a simple algorithm that allows any organizer reading it to calculate the cost of the trip (to determine how much each student should contribute). (p. 70)
The translation of Navas-López’s (2021) problem p4 is:
As you know, most buses entering our country for use in public transportation have their original seats removed and replaced with others that have less space between them to increase capacity and reduce comfort. The company 'Tight Fit Inc.' specializes in providing this modification service to public transportation companies when they 'bring in a new bus' (which we already know is not only used but also discarded in other countries). Write an algorithm for the operational manager (the head of the workers) to perform the task of calculating how many seats should be installed and the distance between them. Assume that the original seats have already been removed, and the 'new' ones are in a nearby warehouse, already assembled and ready to be installed. Since the company is dedicated to this, it has an almost unlimited supply of 'new' seats. (p. 71)
To assess the students’ procedures, the researcher employed the dedicated rubrics for these problems outlined by Navas-López (2021, pp. 77-98). Scores on a scale from 0 to 100 were assigned to the variables: p2.input, p2.output, p2.idsub, p2.solsub, p2.intsub, p2.norm, p2.extre, p2.flow, p2.syn, p4.input, p4.draw, p4.output, p4.idsub, p4.solsub, p4.intsub, p4.norm, p4.extre, p4.flow, p4.syn.
These 19 observable variables have been grouped in four different ways to construct the models for evaluation. The first group of models includes all 19 variables separately (p2&p4). The second group of models includes only the variables related to the first problem (p2). The third group of models includes only the variables related to the second problem (p4). Finally, the fourth group of models comprises intermediate variables obtained from the average of the corresponding variables in both problems (p2+p4), as follows:
-input:= (p2.input + p4.input)/2
-draw:= p4.draw
-output:= (p2.output + p4.output)/2
-idsub:= (p2.idsub + p4.idsub)/2
-solsub:= (p2.solsub + p4.solsub)/2
-intsub:= (p2.intsub + p4.intsub)/2
-norm:= (p2.norm + p4.norm)/2
-extre:= (p2.extre + p4.extre)/2
-flow:= (p2.flow + p4.flow)/2
-syn:= (p2.syn + p4.syn)/2
To assess the feasibility of conducting factor analysis on these four ways of grouping the observable variables, the researcher performs a data adequacy analysis. For assessing reliability, the Cronbach’s alpha coefficient was utilized, and to evaluate construct validity, a CFA was applied to the models described in Table 3. All calculations were carried out using R language, version 4.3.2.
Table 3: Conformation of the evaluated factorial models
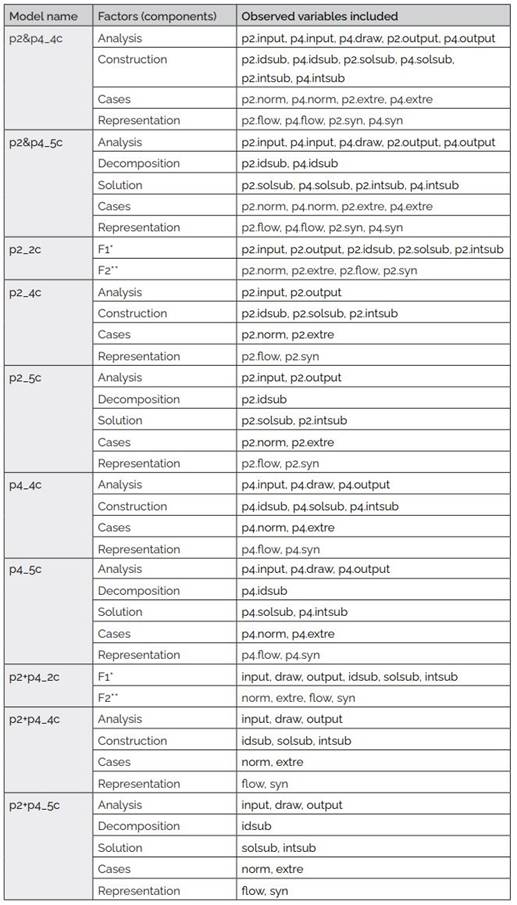
Note. *General solution, **Particular cases and representation.
To evaluate the different models, the absolute fit indices chi-square (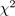 ), relative chi-square (
), relative chi-square (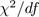 ), RMSEA, SRMR, and the incremental fit indices TLI, CFI, NFI, and GFI were used. The evaluation was based on the respective cut-off values recommended by Jordan Muiños (2021) and Moss (2016), as presented in Table 4.
), RMSEA, SRMR, and the incremental fit indices TLI, CFI, NFI, and GFI were used. The evaluation was based on the respective cut-off values recommended by Jordan Muiños (2021) and Moss (2016), as presented in Table 4.
Table 4: Indices’ cut-off values for Confirmatory Factor Analysis

Note. Own elaboration based on criteria from Jordan Muiños (2021) and Moss (2016).
Results
Of the 88 students, 82 attempted to solve problem p2 (6 did not attempt), 76 attempted to solve problem p4 (12 did not attempt), and 70 attempted to solve both problems. Everyone attempts to solve at least one problem. Cronbach’s Alpha for problem p2 was 0.84, for problem p4 was 0.85, and for both problems (all data) was 0.88. Anderson-Darling test was applied to determine normality, and results showed no one observed variable are normal.
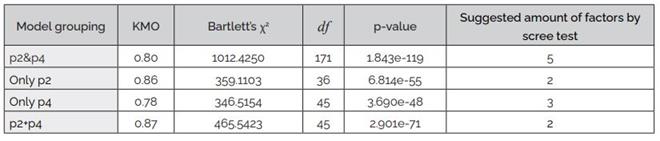
Kaiser-Meyer-Olkin measure was computed to assess the adequacy of the data for conducting a factor analysis. Additionally, Bartlett's test of sphericity was employed to determine whether there was sufficient correlation among the variables to proceed with a factor analysis. The scree test was also utilized to calculate the minimum number of recommended factors. This test defined the two-component models. The results presented in Table 5 reveal that there was a significant relationship among observable variables within four model groupings, supporting the feasibility of conducting a CFA.
For CFA, the WLSMV estimator (weighted least squares with robust standard errors and mean- and variance-adjusted test statistics) was used, following Brown's (2006) recommendations for ordinal, non-normal observable variables.
Corresponding indices were calculated for all models. Table 6 displays the calculated indices. All models achieve good values for incremental fit indices. However, models p2&p4_4c and p2&p4_5c fail in all absolute fit indices. Models p2_2c and p2+p4_2c do not successfully meet all absolute fit indices. For models p2_5c, p4_5c, and p2+p4_5c, all directly based on operationalization in Table 1, it was impossible to compute standard errors in CFA. Since standard errors represent how closely the model's parameter estimates approximate the true population parameters (Brown, 2006), all models with 5 components (factors) must be discarded.
Table 6: Results from the CFA conducted
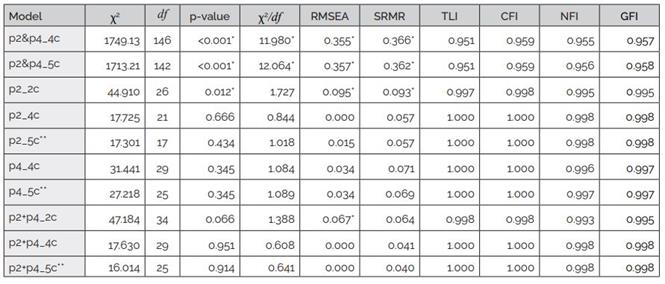
Note. *Does not meet according to cut-off values in Table 4. **Could not compute standard errors.
Only last three models with 4 components (factors) has very good psychometric properties. They are very similar to operationalization in Table 1, but in these models, decomposition-related observed variables (p2.idsub and p4.idsub) are placed together with algorithm-construction-related variables (p2.solsub, p2.intsub, p4.solsub and p4.intsub) inside the same factor. The factor loadings of these three models are shown in Table 7.
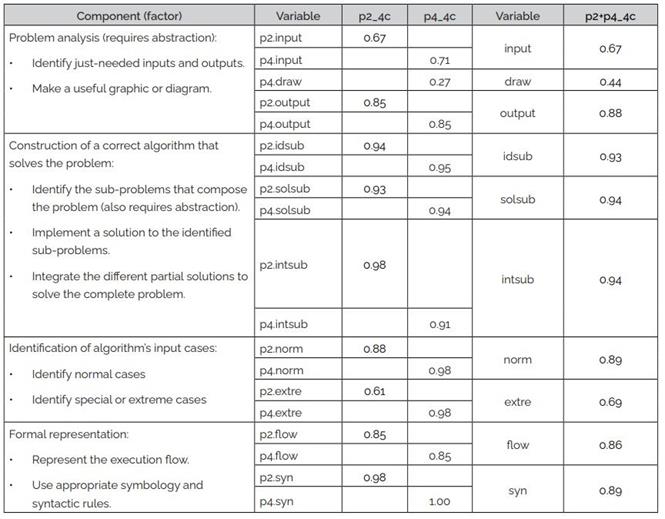
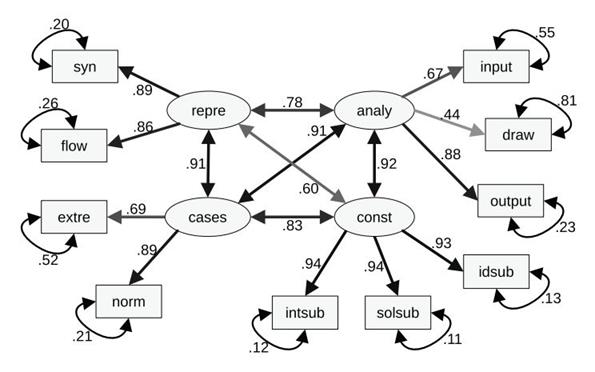
Figure 2 displays the structural equation modelling (SEM) diagram for the p2+p4_4c model, depicting factor loadings, residuals, and covariances between factors. Notably, only one-factor loading is relatively weak and pertains to the variable "draw." Conversely, all other factor loadings exhibit reasonably high values.
Discussion and conclusion
Grading consistency can be challenging, but rubrics serve as a standard scoring tool to reduce inconsistencies and assess students' work more efficiently and transparently (Chowdhury, 2019). Rubrics are crucial for evaluating complex cognitive skills like AT. Although analytic rubrics can slow down the scoring process because they require examining multiple skills individually (Mertler, 2001), their detailed analysis is valuable for understanding and developing AT (Lehmann, 2023).
Constructing reliable open-ended problems to assess AT is challenging due to the relation between problem complexity and students’ prior experience. Thus, several considerations are essential: using a standard complexity metric for algorithms (Kayam et al., 2016), employing a general rubric for assessing CT activities (Otero Avila et al., 2019), and adapting problem complexity to students' levels (Bubica & Boljat, 2021).
The lack of consensus on the differences between CT and AT hinders the development of a standard rubric for AT. For instance, Bubica and Boljat’s (2021) and Ortega Ruipérez and Asensio Brouard’s (2021) interpretations of CT align with Stephens and Kadijevich’s (2020) interpretation of AT. These diverse interpretations complicate the validation of their operational definitions.
Despite these difficulties, the design, construction, and construct validation of an assessment rubric for AT represent a valuable effort. Evaluating CT (Poulakis & Politis, 2021) and AT (Stephens & Kadijevich, 2020) remains an urgent concern for educational researchers. Therefore, any endeavor to advance towards a comprehensive operational definition of AT with both content and construct validity must be greatly appreciated.
In this study, the CFA conducted on undergraduate students (aged 17-33) led to an operational definition for AT composed of four components: Problem analysis, algorithm construction, input cases identification, and algorithm representation (as shown in Table 7). This result is confirmed by the good psychometric properties of the three four-factor models, with the two problems considered separately, p2_4c and p4_4c, and with the averaged results from both problems, p2+p4_4c (see Table 6).
These results provide more detail than the two-factor model (problem representation and problem-solving) by Ortega Ruipérez and Asensio Brouard (2021) for adolescents and the unifactorial model by Lafuente Martínez et al. (2022) for adults. However, comparability with Bubica and Boljat (2021) and Sung (2022) is limited, as both focus on children, and their models' factor loadings and psychometric properties are unsatisfactory. This may be due to children's ongoing cognitive development, as Sung (2022) notes. Indeed, higher-order thinking skills, such as complex problem-solving, develop as children transition to adolescence (Greiff et al., 2015).
However, there are significant limitations to consider. The sample size of 88 subjects is relatively small, potentially limiting the generalizability of the results. Moreover, the use of convenience sampling introduces bias, making it unclear if the sample represents all undergraduate students. These limitations underscore the need for cautious interpretation and highlight the necessity for future studies with larger, more diverse samples to validate these findings.
Furthermore, Navas-López's (2021) operational definition for AT lacks complete construct validation, particularly regarding the "running" component (see Table 1). Future research should address this by employing larger samples and using a comprehensive instrument (including a broader rubric) that evaluates a range of problems, akin to p2 and p4, for grading the initial 10 variables, alongside proposed algorithms for the run and err variables (see Table 2).
In conclusion, while this study advances toward a detailed operational definition of AT, the sample size and sampling method constraints must be acknowledged. Continued research is crucial to strengthen the reliability and applicability of these findings, thereby facilitating the development of robust assessment tools for AT.

