











 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo

 Permalink
Permalink
Introducción
Como se ha señalado varias veces, “inteligencia artificial” (IA) es un término equívoco, que no responde a una definición precisa y que más bien funciona como un paraguas bajo el que se cobijan desarrollos tecnológicos y problemáticas diversas. Es posible encontrar la idea de emular el cerebro humano en los mismos orígenes de la informática y, de hecho, la propuesta que Alan Turing realizó para evaluar si una máquina podía exhibir un comportamiento inteligente (el famoso “test de Turing”) fue realizada en 1950.
Pero el desarrollo de las tecnologías necesarias fue discontinuo y atravesó etapas carentes de progresos significativos (los “inviernos de la IA”). Es recién en los últimos 15 años, con el desarrollo de nuevos abordajes en la programación (machine learning, deep learning), el incremento de la capacidad de cómputo del hardware y -especialmente- la disponibilidad de enormes bancos de datos, que la IA se vuelve un conjunto de tecnologías de aplicación efectiva en un número cada vez más amplio de campos.
En forma correlativa, la IA -que podemos definir ampliamente como “ideas, tecnologías y técnicas que se relacionan a la capacidad de sistemas de computación para desarrollar tareas que normalmente requieren inteligencia humana” (Scott Brennen et al., 2018, pp. 1-2)- se ha vuelto un tópico cada vez más habitual en el tratamiento informativo, sin limitarse a las secciones o medios especializados. Si bien en varias investigaciones se registra un notable crecimiento en la atención mediática (al menos para el contexto anglosajón) a partir de fines de la primera década de este siglo (Bunz & Braghieri, 2022; Fast & Horvitz, 2017; Sun et al., 2020), sin dudas el desarrollo específico de IA generativas y su puesta a disposición de forma accesible han implicado un salto en el conocimiento general, en el uso y en la atención mediática, con el lanzamiento de ChatGPT como buque insignia de esta tendencia.
Es preciso situar el interés por el tratamiento periodístico de la IA en el contexto más general del estudio de los procesos de apropiación de tecnologías. En los últimos años, en esta área de trabajo se han discutido conceptualizaciones, modelos analíticos e investigaciones empíricas que buscan superar la focalización anterior en los usos de las tecnologías para abarcar procesos de mayor complejidad, sin abandonar el rechazo al determinismo tecnológico y el acento en la capacidad de agencia de los sujetos en sus encuentros y usos de dispositivos tecnológicos (Cabello & Lago Martínez, 2023; Cabello & López, 2017; Morales & Loyola, 2013).
Desde esta perspectiva, la apropiación de tecnologías puede entenderse como un proceso (histórico) en el cual un ingenio técnico (hardware, software o conjuntos complejos de ambos) pasa de la inexistencia a ser incluido en la cotidianidad de personas y grupos, para lo cual deben atravesarse un conjunto de fenómenos socioculturales y condensarse una multitud de sentidos. Desde un punto de vista analítico, pueden diferenciarse una serie de momentos: el desarrollo técnico, las regulaciones, las estrategias empresarias y los usos, que pueden analizarse en forma autónoma o en sus interrelaciones (Sandoval, 2020).
Ahora bien, a lo largo de todo el proceso de apropiación de una tecnología, cada momento es acompañado y atravesado por una multiplicidad de discursividades que enmarcan, contextualizan y vuelven inteligibles los dispositivos y sistemas tecnológicos, desde los anuncios publicitarios (Campbell et al., 2021; Goggin, 2015; Sandoval, 2019) hasta los textos ficcionales (novelas, films, series televisivas, telenovelas), pasando por la profusión de reviews y unboxings de distintos gadgets por parte de youtubers o usuarios comunes (Mowlabocus, 2020; Rajaram & Manchanda, 2023) y también por los discursos periodísticos. Estos últimos son el foco del presente trabajo.
La plataformización ha supuesto y supone un enorme desafío para los medios informativos tradicionales, para sus modelos de negocio, sus rutinas productivas y sus modos de vinculación con las audiencias (van Dijck et al., 2018). Si bien la producción social de sentido no se encuentra confinada a sus límites, si es que alguna vez lo estuvo, es un error considerar que han pasado a ser irrelevantes, ya que “se mantienen en una posición fuerte para alcanzar al público, sintetizar puntos de vista de diversas partes interesadas en una forma resumida e influir en el direccionamiento de la atención social a cuestiones específicas” (Nguyen & Hekman, 2022, p. 3). Tanto en los procesos de establecimiento de agenda como de enmarcado (Aruguete, 2015; Castells, 2009; Entman, 2003; McCombs, 2006), los medios informativos mantienen un rol preponderante, y esto parece ser aún más significativo en lo que hace al ámbito del desarrollo científico y tecnológico (Pentzold & Fischer, 2017) e incluso desplegarse aun con más nitidez en lo que hace a la IA, ya que, como expresan Gómez-Calderón y Ceballos (2024), en una posición compartida por otros investigadores,
la irrupción de la IA en la agenda informativa global es relevante por cuanto la concepción que la sociedad tenga de ella depende en gran parte de su cobertura periodística, y también en la medida en que el tratamiento mediático puede condicionar el desarrollo futuro de la inteligencia artificial y los controles que se le apliquen (Gómez-Calderón & Ceballos, 2024, p. 286).
Esta perspectiva ha animado un conjunto reciente de investigaciones que buscan analizar la forma en que la IA y temas muy relacionados como el big data se tematizan y discuten en los medios informativos. Desde el punto de vista del dispositivo metodológico utilizado, puede distinguirse entre las que han realizado análisis de contenido cuantitativos tradicionales, las que optan por enfoques de procesamiento automático de lenguaje natural (NLP), las que han apelado a enfoques cualitativos y las que se inclinaron por dispositivos combinados. Entre las primeras, Fast y Horvitz (2017) estudiaron la forma en que la IA fue tratada en The New York Times entre 1986 y 2016, mientras que Scott Brennen et al. (2018) estudiaron artículos publicados en medios británicos durante 2018, analizando tipo de artículo, fuentes, temas recurrentes, tópicos y frames. Por su parte, Chuan et al. (2019) analizaron una muestra de artículos sobre IA publicados en los cinco medios norteamericanos más leídos, buscando determinar tópicos, fuentes y la presencia de riesgos o beneficios, mientras que De Lara (2022) se centró en analizar -en una muestra pequeña de artículos sobre IA publicados en medios en español- el lenguaje utilizado, desde una perspectiva de comunicación de la ciencia. Finalmente, en la investigación más reciente entre las publicadas sobre medios en idioma castellano, Gómez-Calderón y Ceballos (2024) utilizaron el análisis de contenido para abordar una muestra intencional de artículos provenientes de ocho periódicos españoles, centrándose en una tecnología de IA en especial: los chatbots.
Respecto a las investigaciones que han utilizado dispositivos basados en técnicas de NLP, Vergeer (2020) analizó tópicos y tendencias presentes en el tratamiento sobre IA realizado por los medios informativos de los Países Bajos desde 2000, mientras que Zhai et al. (2020) utilizaron este tipo de abordaje para analizar la evolución de la conceptualización de la IA en un grupo de periódicos de referencia de habla inglesa. Estos últimos investigadores detectaron -en un período extenso, entre 1977 y 2018- los cambios en las disciplinas científicas relacionadas a los artículos sobre IA, los tópicos principales en cada período y los actores (países, instituciones y personas) más relevantes por su presencia en el tratamiento mediático. Crépel et al. (2021) se centraron en artículos publicados en un conjunto amplio de medios de habla inglesa que presentaban enfoques críticos sobre la IA y los abordaron desde un análisis semántico con técnicas NLP, lo que les permitió distinguir dos campos semánticos diferentes. Nguyen y Herman (2022) utilizaron el análisis de contenido automático para establecer los frames presentes en las noticias sobre IA en cuatro medios de habla inglesa.
Otras investigaciones apelaron a dispositivos de corte cualitativo: Pentzold y Fisher (2017) estudiaron la cobertura de un caso polémico -de acceso a datos de teléfonos móviles por parte de la fuerza policial alemana- en periódicos, sitios web institucionales y redes sociales mediante una codificación abierta, basada en la teoría fundamentada, sobre un corpus de documentos; Ouchchy et al. (2020) analizaron, mediante codificación abierta, un conjunto de artículos de procedencia diversa (periódicos, revistas, blogs, etc.) recopilados desde la base NexisUni a partir de una búsqueda por términos clave, centrándose en el tratamiento de las cuestiones éticas relacionadas con la IA; Pentzold et al. (2019) se detuvieron en las ilustraciones que acompañaban notas sobre big data en dos periódicos norteamericanos de referencia, con un sistema de codificación abierta; Bunz y Braghieri (2022) analizaron en forma cualitativa un conjunto de artículos sobre el uso de IA en servicios de salud y Becerra (2022), en el único antecedente encontrado para el caso específico de Argentina, analizó las representaciones sociales presentes en la prensa el tratamiento del big data, siguiendo la teoría fundamentada y a partir del abordaje conceptual de las representaciones sociales de Serge Moscovici.
Finalmente, Sun et al. (2020) utilizaron un dispositivo combinado que incluyó varias estrategias en el análisis de un conjunto de 1.776 artículos de periódicos de referencia en lengua inglesa, recopilados a partir de la base LexisNexis: detección de tópicos mediante técnicas NLP, análisis de contenido manual (especialmente para ubicar términos compuestos como indicadores de frames) y análisis de redes.
En este trabajo se pretende realizar un aporte a esta área de interés a partir de una estrategia que combina análisis de contenido automático y manual de artículos sobre IA publicados en cinco medios digitales generalistas argentinos: La Nación, Infobae, MDZ Online, Página/12 y Clarín.
Metodología
A partir de técnicas de web scraping (utilizando la librería BeautifulSoup para Python) se confeccionó un corpus de 1.485 artículos de esos cinco medios en los que se tematiza la inteligencia artificial, la robotización y la automatización de procesos. El scraping se realizó los días 28 de febrero y 1 de marzo de 2023, a partir de búsquedas en Google.1 Se intentó arribar a una instancia donde los artículos rankeados ya no tuvieran mayormente relación con la temática, algo que se lograba hacia los primeros 350 resultados, a excepción de Página/12. La cantidad de notas rankeadas de este medio resultó significativamente menor, por lo que se incluyó la totalidad. Esto explica que los períodos planteen diferencias entre medio y medio: La Nación (03/01/2015 - 28/02/2023), Infobae (04/10/2014 a 28/02/2023), MDZ Online (15/02/2019 a 28/02/2023), Clarín (07/09/2001 a 28/02/2023) y Página/12 (24/02/2002 a 01/03/2023). Luego de capturadas las notas, se revisaron manualmente los títulos y, en los casos que generaban dudas, se consultó el artículo. Se eliminaron duplicados y artículos no relevantes. El corpus final quedó constituido por 1.263 artículos, distribuidos como sigue: La Nación (298), Infobae (316), MDZ Online (205), Clarín (306) y Página/12 (138).
Este corpus fue analizado en dos etapas: en primera instancia se sometió a un abordaje de minería de datos y procesamiento de lenguaje natural, a partir del cual se obtuvieron datos como la extensión promedio de los artículos, palabras más usadas en cada medio (diferenciando títulos, copetes y texto de los artículos), frecuencia de uso de palabras escogidas, correlación en el uso de términos entre los distintos medios, palabras comunes y diferenciadoras y análisis de sentimiento a partir del modelo bert-base-multilingual-uncased-sentiment.2
Posteriormente, se seleccionó una muestra representativa (con cuotas por medio y sección) de n = 295 artículos (Z = 95 %, E = ±5 %) que fue abordada a partir de un análisis de contenido cuantitativo. La matriz de variables incluyó variables periodísticas y temáticas. Entre las primeras: medio, fecha de publicación del artículo, sección y origen (diferenciando entre producción propia y agencia u otro medio). Entre las segundas: área social de impacto de la noticia (salud, educación, etc.), origen geográfico, especificidad de la tecnología, uso de fuentes, posibilidad de uso por el lector, inclusión de reclamos por modificaciones normativas, grado de antropomorfismo y tratamiento de desigualdades sociales. Teniendo en cuenta que los periódicos analizados son publicados en Argentina, que no es uno de los países en que se concentran los desarrollos sobre IA y otras tecnologías de punta, una primera pregunta apunta a esta situación:
R1. ¿Cuál es el origen de los acontecimientos informativos cubiertos por los artículos considerados?, y ¿cuál es la participación de noticias originadas en el propio país?
Una segunda pregunta se relaciona con la primera:
R2. ¿En qué medida los medios analizados producen su propia cobertura sobre la IA o apelan a agencias o noticias publicadas en otros medios?
En algunas de las investigaciones ya citadas (Pentzold et al., 2019; Scott Brennen et al., 2018; Zhai et al., 2020) se ha constatado un predominio de noticias sobre IA provenientes del ámbito empresario y asignando un rol destacado a fuentes empresariales. En función de ello resulta de interés verificar este aspecto para el caso argentino, de lo que se deriva la siguiente pregunta:
R3. ¿Cuáles son las áreas de la vida social que aparecen como más relevantes a la hora de informar sobre IA?, y ¿cuáles son los tipos de fuentes más habituales?
Por otra parte, al analizar tanto las coberturas periodísticas sobre desarrollos tecnológicos como la percepción pública de estos, es habitual diferenciar sus posibles beneficios y probables riesgos o, como señalan Cave y Dinhal (2019), cuya propuesta analítica se retoma en este trabajo, las esperanzas o expectativas y los temores que generan. En este sentido, la cuarta pregunta de investigación es:
R4. ¿Qué expectativas y temores están más presentes en los artículos analizados?, y, en consecuencia, ¿el tratamiento de los medios estudiados puede considerarse más bien optimista o pesimista respecto al despliegue de la IA y los procesos de automatización?
Una última pregunta refiere al grado de consonancia en el tratamiento de los distintos medios. La selección de medios se realizó con base en que se encuentran entre los sitios de noticias digitales argentinos más consultados. Todos los medios seleccionados estaban entre los diez más leídos en 2022, según ComScore (“Infobae cerró el 2022”, 2023), pero también responden a líneas editoriales y modelos organizacionales muy diferentes.3 De allí la pregunta:
R5. ¿Qué grado de similitud o diferencia existe en el tratamiento de la IA entre los distintos medios considerados?
La codificación y el análisis de contenido se llevó a cabo utilizando el software Dokumentoj.
Resultados
Dónde suceden los acontecimientos
Desde la perspectiva de un país periférico como Argentina, el desarrollo de la IA y las tecnologías de automatización es algo que sucede mayormente en otra parte, en los “países adelantados” (Figura 1). Esto explica la baja participación de noticias originadas en el propio país o en la región, que en conjunto no llegan a una quinta parte de todas las noticias. Claramente, el lugar en donde se producen los acontecimientos relacionados con esta temática es en los países desarrollados y muy especialmente Estados Unidos, de donde proviene la mitad de las noticias de las cuales se pudo identificar un origen geográfico (para un quinto de los artículos esto no se pudo precisar).
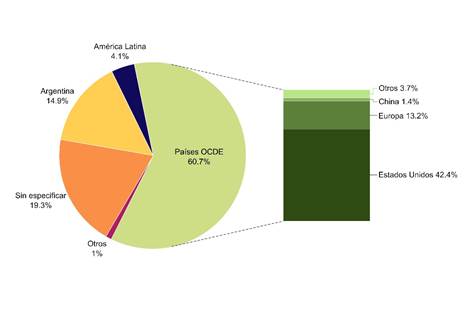
Scott Brenenn et al. (2018) indican que muchos medios han recortado sus planteles y eliminado a periodistas especializados, incluyendo los de ciencia y tecnología. Es razonable suponer que esto ha sucedido también en el caso local. Si a esta falta de periodistas especializados se le suma el hecho de que la IA se ha convertido en un tema de interés en la actualidad, se puede explicar que se publiquen muchos artículos sobre el tema más bien intrascendentes. No es el caso, en general, de los artículos que toman como objeto acontecimientos de origen local, en los que abundan aquellos de producción del propio medio (más de cuatro quintos) y en muchos de los cuales se informa sobre desarrollos tecnológicos nacionales. La Nación y Página/12 destacan en este sentido. En el primer caso, casi un cuarto de las noticias publicadas refiere a acontecimientos locales, entre los que se destacan los desarrollos vinculados a la agroindustria (“Crearon un sistema para aplicar IA en las pulverizaciones agrícolas”, La Nación, 3/12/2019; “Inteligencia artificial: un desarrollo clave para cereales y lo que viene”, La Nación, 25/10/2918) o la cobertura de eventos auspiciados por el mismo medio.
Quién produce la información
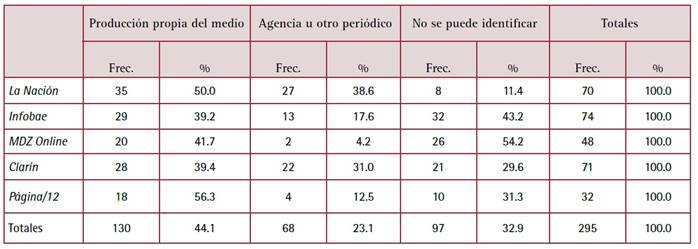
En el total de artículos considerados en la muestra, los que son de producción propia de cada medio no llegan a la mitad (Tabla 1). Un cuarto de las notas proviene de agencias o de otros medios (artículos publicados por convenio y provenientes de periódicos norteamericanos, europeos o de otros países de América Latina). Pero en un tercio de los artículos no pudo identificarse el origen de la producción; en muchos casos hay indicios de que se trata de material de prensa producido por las empresas tecnológicas, más o menos adaptado (por ejemplo: el mismo día Infobae publica la noticia “Spotify lanza su propio DJ con inteligencia artificial” y Clarín la noticia “Spotify apunta a la inteligencia artificial: lanza un DJ personalizado con voz humana”, 22/10/2023). De cualquier manera, al menos para este tema, la práctica de publicar artículos que no identifican el origen de su producción está bastante extendida y parece aún más característica de los medios “nativos digitales”, donde promedian casi la mitad de los artículos, contra el 24 % que promedian los publicados en las ediciones digitales asociadas a medios en papel.
De qué se habla, quién lo hace
La sección donde se ubica cada artículo en un periódico ha sido considerada habitualmente como un primer marcador de enmarcado (Olmo et al., 2012). En este caso la sección fue detectada en la etapa de scrapping, donde se encontró que los criterios asumidos en cada medio no eran equivalentes, con discrepancias particulares en los casos de MDZ Online y Página/12. Luego de normalizar y agrupar las secciones de cada medio, se culminó con las presentadas en la Figura 2, que sirvieron a su vez como uno de los criterios -junto al medio- para establecer las cuotas de la muestra.
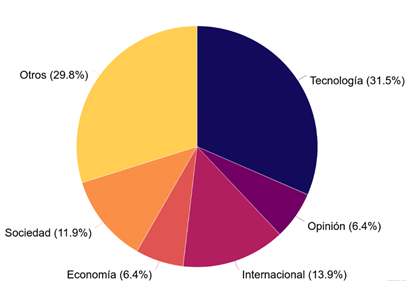
La sección Sociedad es más utilizada en MDZ Online y Página/12. En el primer caso incluye artículos que en otros medios bien pueden incorporarse a Tecnología (sucedió así, entre otros casos, con la misma noticia sobre una IA generativa de Google que produce música a partir de instrucciones textuales, incluida en Sociedad en MDZ Online y en Tecnología en La Nación). Teniendo en cuenta estas discrepancias, puede verse que la información sobre el tema del presente estudio se enmarca en un porcentaje importante en secciones específicas denominadas Tecnología. El criterio para asignar una nota a Internacional no se limita al origen foráneo de la noticia (ya que, como se vio, el 85 % de los artículos cumplen con este requisito) sino, en muchos casos, a su procedencia de una agencia o de otro periódico (lo que sucede con más de la mitad de las notas publicadas en esta sección). Respecto a las que se enmarcan en Economía, hay artículos que presentan innovaciones para sectores productivos específicos (especialmente la agroindustria), otros que analizan el impacto de la IA en la contratación de personal y la administración de recursos humanos y algunos comentarios sobre la competencia comercial entre las grandes empresas tecnológicas (o geopolítica entre Estados Unidos y China). La sección Otros agrupa tópicos diversos de representación minoritaria: Entretenimiento y espectáculos, Estilo de vida, Deportes, Salud, etcétera. Como se ve, la sección no es un buen predictor del contenido y enfoque del artículo, ya que en muchos casos la misma nota podría incluirse en distintas secciones en cada medio, o incluso en el mismo medio. Por ejemplo, para La Nación el artículo “Un artista recreó con inteligencia artificial cómo se verían las provincias argentinas si fueran villanos de película” (23/02/2023) es parte de Tecnología, mientras que “Un usuario creó dinosaurios profesionales con inteligencia artificial y el resultado causó furor en las redes” (8/2/2023) corresponde a la sección denominada Lifestyle.
Si se enfoca en el área de incidencia de la noticia (variable definida como “área social en la cual impacta la innovación, desarrollo o producto”), se puede ver que las más habituales son, en este orden: “Economía y empresas”, “Aplicación general” y “Entretenimiento y ocio” (Tabla 2).
Tabla 2: Área social de incidencia de la noticia según fuentes citadas (n = 252)
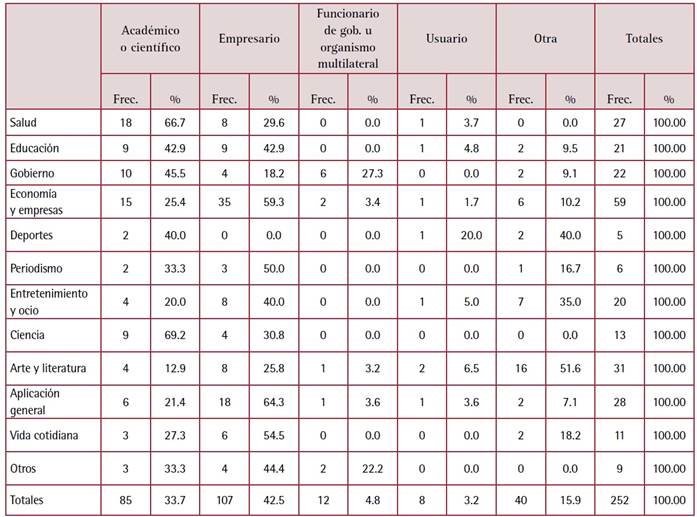
Nota: Se consideró el total de tipos de fuentes para los artículos donde se mencionaba al menos un área de incidencia de la noticia.
El área “Economía y empresas” agrupa artículos sobre innovaciones específicas para algunos sectores económicos (nuevamente se destaca la agroindustria), sobre el impacto de la IA y la automatización en la pérdida de empleos (o en su redefinición), los que se centran en herramientas para la administración de recursos humanos y un conjunto de artículos que analizan aspectos de la competencia entre las grandes firmas tecnológicas.
Por su parte, “Aplicación general” reúne un conjunto de artículos que refieren a distintos aspectos de la IA, pero sin vincularlos a algún tipo de aplicación más específica. Es el caso de notas sobre avances en el desarrollo de la IA que permiten que imite voces humanas (“Microsoft desarrolló una inteligencia artificial que imita voces humanas a partir de audios de tres segundos”, Página/12, 11/01/23), traduzca idiomas (“Meta presentó la primera Inteligencia Artificial que traduce idiomas a través del habla”, MDZ Online, 27/10/22) o incluso cuente chistes (“Avances en la Inteligencia Artificial: Google creó un bot que entiende y puede explicar chistes”, Infobae, 11/04/22). En todos estos casos se presenta un avance o una preocupación (“El alter ego de Elon Musk reveló por qué la inteligencia artificial puede dar miedo”, MDZ Online, 22/02/23) que puede vincularse a distintas áreas de la vida social, incluso a todas, pero sin que se especifiquen estos potenciales vínculos.
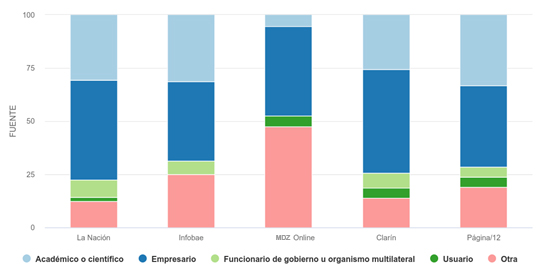
Respecto a las fuentes citadas (Figura 3), las más habituales corresponden a empresarios (42 %), a los que le siguen los académicos y científicos (33 %). Son llamativos los porcentajes exiguos tanto de funcionarios (ya sea de gobiernos nacionales o de organismos multilaterales) como de usuarios. Los empresarios son las fuentes más consultadas cuando el tema es “Economía y empresas”, pero también para “Aplicación general”, “Vida cotidiana” y “Entretenimiento y ocio”, mientras que los académicos y científicos lo son para las áreas “Salud”, “Gobierno” y “Ciencia”. “Educación” apela igualmente como fuentes a académicos y empresarios. La distribución general para cada medio es similar, con la excepción de MDZ Online, donde el porcentaje de científicos es menor y en cambio es más significativo el de otras fuentes (especialmente artistas y deportistas).
Expectativas y temores
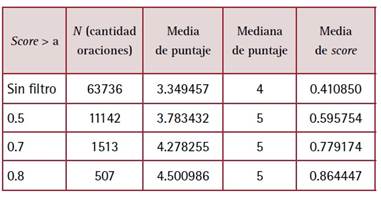
Un primer acercamiento al tratamiento que realizan los medios aquí analizados sobre la IA y la automatización puede lograrse a partir de técnicas de análisis de sentimiento. En este caso se utilizó (a partir de una librería de Python) el modelo bert-base-multilingual-uncased-sentiment. A diferencia de otros modelos que contrastan las palabras del corpus con un diccionario de valencias de términos predefinidos, este algoritmo analiza el texto tokemizado en oraciones y en forma nativa para seis idiomas (inglés, holandés, alemán, francés, italiano y español). El algoritmo adjudica un puntaje (label) de 1 a 5 para cada oración (que puede asimilarse a una escala de Likert de 1: muy negativo a 5: muy positivo). Además, asigna a cada oración un score que es el valor (entre 0 y 1) de confiabilidad respecto a la evaluación que realiza el mismo algoritmo.4
El corpus del presente estudio está conformado por 1.263 artículos en los que se detectaron 63.736 oraciones. Los scores asignados van de 0.206441 a 0.946185 con una media de 0.410850, por lo que podría decirse que la confiabilidad del análisis del algoritmo no es muy alta para todo el corpus. Teniendo en cuenta esto último, puede limitarse el análisis a scores más altos (oraciones con evaluación más confiable), de lo que se obtienen los resultados de la Tabla 3. Vale decir que la connotación es mayormente positiva, con una mediana de 4 (positiva) y una media de 3.35 para el total del corpus, valor que se incrementa de manera consistente a medida que el conjunto de oraciones analizadas se restringe a las de evaluación más confiable.
Avanzando hacia el análisis de los beneficios o riesgos que se presentan para este tipo de tecnologías, en esta investigación se adoptó (y adaptó) la propuesta analítica de Cave y Dihal (2019) para su análisis de un conjunto de textos de ficción y no ficción sobre IA. Estos autores propusieron cuatro ejes, cada uno con una expectativa o esperanza en un extremo (inmortalidad, comodidad, gratificación y dominio) y un temor en el otro (deshumanización, obsolescencia, alienación y revuelta). Además de estas ocho posibilidades, la adaptación supuso incluir una expectativa y dos temores presentes en la muestra pero no considerados originalmente: la expectativa es el alcance (posibilidad de realizar acciones vedadas para los seres humanos o de dificultad y riesgos enormes para ellos), mientras que los temores añadidos son el engaño (posibilidad de adjudicar origen humano a una acción o producto desplegado por una IA, o de tomar decisiones basadas en información errónea suministrada por la tecnología) y la vigilancia (uso de la tecnología para controlar o vigilar a las personas, especialmente por parte de estados autoritarios).
Tres cuartas partes de los artículos de la muestra (n = 295) incluyen la apelación a alguna expectativa/esperanza o a algún temor, de los cuales algo más de la mitad solo menciona esperanzas, un tercio tanto esperanzas como temores y solo un 15 % se limita a estos últimos (Figura 4).
Si la expectativa más común es la comodidad (definida como la simplificación de las tareas laborales a partir de la automatización), con un 45 % de todas las expectativas mencionadas, el temor más habitual es su polo opuesto, la obsolescencia (sustitución de puestos de trabajo por robots o IA), que llega al 39 % de los temores presentados. Con todo, si bien los porcentajes son similares, debe tomarse nota de que las expectativas casi duplican a los temores, por lo que los valores absolutos son de 94 contra 48 para ambos casos. La segunda expectativa mencionada es la gratificación (experiencias de disfrute logradas a partir del uso de tecnologías avanzadas), pero su par antitético, la alienación (dificultad para sostener relaciones auténticas con otros seres humanos) es la única posibilidad entre todas las expectativas y temores que no tiene ninguna mención. En su lugar, el segundo temor más recurrente es uno de los que agregamos en esta investigación: el engaño (posibilidad de adjudicar origen humano a una acción o producto desplegado por una IA, o de tomar decisiones basadas en información errónea suministrada por la tecnología).
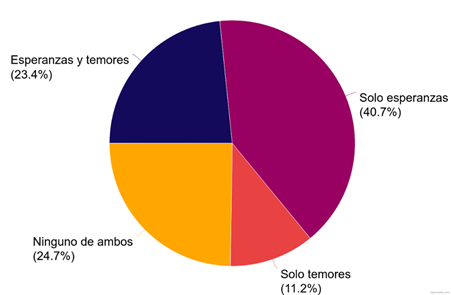
Casi un cuarto de los artículos relevados no incluye apelaciones ni a expectativas ni a temores. ¿Cuál será entonces la perspectiva que plantean? En muchos casos se trata de artículos que comentan algún avance o innovación, a veces incluso comparando con habilidades humanas, pero sin discutir su aplicación ni su impacto social. Ejemplos de esto son una nota (originalmente publicada en The Washington Post) donde se discute la calidad de las poesías producidas por ChatGPT (“La inteligencia artificial escribe poemas mejor de lo que esperábamos”, Infobae, 22/02/23) y otras en las que se comentan lanzamientos de aplicaciones, especialmente por parte de las grandes tecnológicas (“Meta lanzó un nuevo modelo lingüístico basado en inteligencia artificial”, Página/12, 25/02/23 o “GPT-4: qué podrá hacer el próximo sistema de inteligencia artificial más avanzado”, MDZ Online, 31/01/23). Un subconjunto que se ha vuelto cada vez más habitual es el que no se centra en una aplicación o innovación, sino en el producto de una IA generativa, casi siempre como notas de color o que buscan el clickbait (“Una inteligencia artificial mostró cómo se verían Messi y otros jugadores del Mundial de viejos”, MDZ Online, 23/01/23, “Un artista recreó con inteligencia artificial cómo se verían las provincias argentinas si fueran villanos de película”, La Nación, 23/02/23).
Similitudes y diferencias
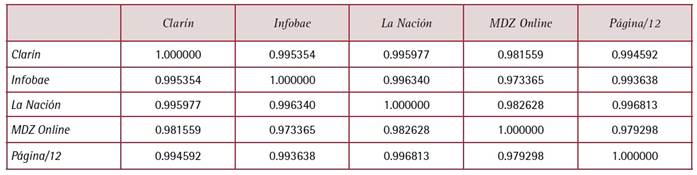
La última pregunta de investigación refiere al grado de similitud o diferencia entre los medios analizados que, como se dijo más arriba, responden a líneas editoriales y modelos organizacionales muy diferentes. Pese a ello, para este tema prima la consonancia. Comparando el conjunto de palabras que utiliza cada medio (luego de aplicar stop words) con los que utilizan los demás, y aplicando una medida estándar,5 se encuentran valores notoriamente altos, cercanos en todos los casos al máximo posible (Tabla 4), lo que indica que el conjunto de palabras que utilizan los cinco medios al referirse al tema son prácticamente idénticos.
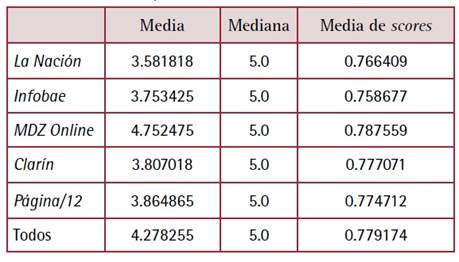
Respecto al análisis de sentimiento, ahora diferenciado por medio y limitado a scores mayores a 0.7, se observa que en todos los casos la mediana es el valor más alto de la escala (afirmaciones más positivas), con promedios que van desde 3.81 (Clarín) a 4.75 (MDZ Online).Tabla 5
A su vez, las diferencias entre los medios no son demasiado significativas al considerar las distintas variables analizadas en la muestra (n = 295). Salvo los casos de Infobae y MDZ Online, en los que el porcentaje más alto es el de los artículos de los cuales no se puede identificar el origen de su producción, para La Nación, Clarín y Página/12 la producción propia es predominante (con porcentajes que van del 39 al 56 %). Estados Unidos es la región geográfica en la que se originan la mayor parte de las noticias publicadas, en todos los casos (en Página/12 el 34 %, valores que trepan al 50 % para Infobae y MDZ Online.
En lo que hace al área social de que tratan las noticias existe una mayor dispersión: para La Nación, Clarín y Página/12 las más numerosas son las de “Economía y empresas”, mientras que en Infobae y MDZ Online son las de “Entretenimiento y ocio”. Los tipos de fuentes más citadas son los empresarios, salvo para Infobae (en donde igualan con académicos o científicos) y Página/12, donde estos últimos son algo más numerosos. En lo que hace a las esperanzas o expectativas presentes, la comodidad es la más común en todos los casos, a excepción de Página/12 donde predomina el alcance. Y respecto a los temores, la obsolescencia es predominante en La Nación, MDZ Online y Clarín, mientras que la revuelta lo hace en Infobae. En todos los casos las expectativas son más habituales que los temores, con relaciones que van desde 1.3 (Página/12) hasta 2.3 (Infobae).
Discusión
En el análisis realizado de las noticias sobre IA y automatización en cinco medios digitales generalistas argentinos parece claro que el tema concita una importante atención y no son escasos los artículos sobre este. Su tratamiento presenta similitudes, pero también diferencias con los hallazgos de otras investigaciones recientes que analizan la cobertura de la IA y temas como el big data en medios periodísticos de otros países, especialmente de Estados Unidos y Europa Occidental.
La respuesta a la primera pregunta (“¿Cuál es el origen de los acontecimientos informativos cubiertos por los artículos considerados?, y ¿cuál es la participación de noticias originadas en el propio país?”) es un caso de diferencia obvia: el hecho de que los países mencionados sean las locaciones principales del desarrollo de estas tecnologías hace que ni siquiera sea una variable analizada. Pero para Argentina, un país periférico en términos económicos y geopolíticos, es importante consignar que las noticias sobre la IA mayormente hablan sobre acontecimientos que “suceden en otro lado”, muy especialmente en Estados Unidos. Así y todo, es destacable que un grupo de medios (aquellos que no son “nativos digitales”) incluye un conjunto de producciones propias que informan sobre desarrollos tecnológicos nacionales, especialmente los vinculados a sectores productivos.
Respecto a la segunda pregunta (“¿En qué medida los medios analizados producen su propia cobertura sobre la IA o apelan a agencias o noticias publicadas en otros medios?”), nuevamente encontramos diferencias entre medios “nativos” y “migrantes” digitales. Si bien en el total de artículos considerados en la muestra los que son de producción propia de cada medio no llegan a la mitad (y el valor más alto no la supera en mucho: 56 % para Página/12), los primeros (Infobae y MDZ Online) se caracterizan por altos porcentajes de artículos de los cuales no se consignan el origen, con la sospecha de que muchos de estos se originan en gacetillas de las empresas tecnológicas. En el grupo de los medios “migrantes”, además de ser algo más altos los porcentajes de producción propia, también lo son los de noticias que adjudican su origen a agencias o periódicos de otros países.
La tercera pregunta (“¿Cuáles son las áreas de la vida social que aparecen como más relevantes a la hora de informar sobre IA?, y ¿cuáles son los tipos de fuentes más habituales?”) apunta a los contenidos de los artículos sobre IA y automatización, así como a los enunciadores legitimados para hablar sobre este tema. Un primer hallazgo es que, si bien las secciones de Tecnología se han vuelto habituales, de ninguna manera contienen a la mayor parte de los artículos sobre la temática. La IA se ha vuelto un tópico general que se discute en términos tecnológicos, pero también económicos y geopolíticos. Además, se ha vuelto una fuente de notas de color o pasatistas, aquellas que se publican en la búsqueda del clic, un resultado coincidente con el de Gómez-Calderón y Ceballos (2024) que -en su análisis de periódicos españoles-encontraron que, junto a reportajes, entrevistas y noticias, “aparecen de forma ocasional textos situados entre el periodismo de servicios, el divulgativo y el que podemos considerar meramente recreativo, basados en creaciones de los propios chatbots” (p. 291).
Entre las áreas sociales de incidencia de la noticia, la más habitual es “Economía y empresas” y los empresarios son las fuentes más citadas -no solo cuando se trata de noticias económicas, sino también en otras áreas- mientras que el segundo tipo de fuentes son los académicos o científicos. Debe tenerse en cuenta que el “enfoque empresarial” no queda confinado al área específica, tal como quedó definida en esta investigación, ya que también puede abarcar, y de hecho lo hace, noticias sobre entretenimiento (donde las noticias que presentan aplicaciones o servicios destacan la empresa que las ha desarrollado) y las que aquí reunimos en “Aplicación general”, que no refieren a una aplicación específica pero que también suelen destacar a las empresas desarrolladoras (“Google creó un bot que entiende y puede explicar chistes” o “Meta presentó la primera Inteligencia Artificial que traduce idiomas a través del habla”).
Este predominio del enfoque empresarial parece una tónica general y los hallazgos son coincidentes con los realizados en investigaciones de otras latitudes. Scott Brennen et al. (2018) encontraron en su análisis de medios británicos que cerca del 60 % de los artículos se referían a productos industriales, iniciativas o anuncios, noticias gubernamentales (18 %) y noticias derivadas de la investigación científica (16 %), y que esto era congruente con el hecho de que el 33 % de las fuentes eran empresarios, el doble de los académicos y seis veces más que los funcionarios. También Chuan et al. (2019), en su análisis de los medios norteamericanos más leídos, consignan que el tópico más habitual era “Negocios y economía”, mientras que Zhai et al. (2020), luego de analizar los nombres de personas e instituciones que aparecen en su estudio longitudinal, concluyen que “para las noticias de IA, las noticias empresariales han sido siempre el foco de la cobertura” (p. 7). Por otro lado, en la investigación que realizaron sobre las imágenes que acompañan a las notas sobre big data en dos periódicos norteamericanos de referencia, Pentzold et al. (2019) encontraron que la forma de ilustración más habitual son las fotografías de “protagonistas”, que suelen ser varones, estar solos, a distancia íntima o social y mirando a la cámara con expresión amistosa: se trata preferentemente de los CEO de empresas tecnológicas y emprendedores.
El lugar de privilegio que tiene el enfoque empresarial no se condice con la importancia del tema y con la necesidad de que exista un debate público informado. Como expresan Scott Brennen et al. (2018, p. 1):
la discusión pública podría beneficiarse si las organizaciones periodísticas se movieran más allá de las iniciativas y fuentes de la industria, que tienden a focalizar en un solo lado y así pueden socavar una comprensión amplia de la IA como una cuestión pública.
La cuarta pregunta (“¿Qué expectativas y temores están más presentes en los artículos analizados?, y, en consecuencia, ¿el tratamiento de los medios estudiados puede considerarse más bien optimista o pesimista respecto al despliegue de la IA y los procesos de automatización?”) refiere al tono general del tratamiento del tema. De nuevo en forma coincidente con la investigación precedente en el área, el análisis muestra que el tono general es positivo o favorable: el análisis de sentimiento arroja una mediana que está en el tope de la escala (cuando se asegura la confiabilidad con scores superiores a 0.5) y la media crece consistentemente a medida que se incrementa la confiabilidad de las evaluaciones del algoritmo. Por otra parte, en el análisis específico de expectativas o esperanzas y temores se encontró que casi dos tercios de los artículos incluyen los primeros, mientras que los temores solo se encuentran en un tercio de las notas. La expectativa más habitual es la comodidad (simplificación de las tareas laborales a partir de la automatización), mientras que el temor más mencionado es su polo opuesto, la obsolescencia (sustitución de puestos de trabajo por robots o IA). El predominio de una tónica optimista en el tratamiento que los medios informativos hacen de la IA ha sido consignado en varias investigaciones. Fast y Horvitz (2017) encontraron como regularidad la presencia de cerca de tres artículos optimistas por cada uno pesimista a lo largo de un período de 30 años en el tratamiento de The New York Times. Aunque su interés eran los artículos críticos, Crépel et al. (2021), quienes recopilaron casi 30.000 artículos de periódicos norteamericanos y británicos, reconocen que “nuestro corpus de artículos de prensa está compuesto mayormente por contenido no controversial acerca de la IA” (p. 80) y similar hallazgo realiza Becerra (2022) para el caso argentino, en el cual “el tono predominante es mayormente positivo, o incluso promocional” (p. 15). En la misma línea, Sun et al. (2020) encontraron que “los patrones de argumentación orientados a los beneficios (de la IA) aparecen más frecuentemente que aquellos que enfatizan riesgos o limitaciones” (p. 13).
Es cierto que en los resultados de otras investigaciones el tono optimista es más módico. Por caso, en su análisis de la cobertura de chatbots, Gómez-Claderón y Ceballos (2024) encuentran “aspectos tanto positivos como negativos, con ligero predominio de estos últimos” (p. 293), mientras que Ouchchy et al. (2018) -para el caso particular de noticias sobre aspectos éticos del desarrollo de la IA- concluyen que “una cobertura inicialmente optimista y entusiasta fue seguida por tonos mayormente críticos o balanceados en años más recientes” (p. 933).
Ahora bien, habría dos cuestiones a señalar aquí. La primera es que, si bien la tónica optimista ha sido consignada en varias ocasiones para el tratamiento informativo de la IA, lo opuesto ha sucedido en el caso del discurso ficcional, donde lo habitual es un tono pesimista o incluso distópico (Hermann, 2021; The Royal Society, 2018; Sandoval et al., 2022). La segunda cuestión es que un hallazgo de esta investigación, que casi no parece estar consignado en otras, es la existencia de un importante conjunto de artículos de los cuales no puede indicarse que sean pesimistas ni optimistas. Son aquellos que comentan algún avance o innovación, a veces incluso comparando con habilidades humanas, pero sin discutir su aplicación ni su impacto social. O bien no se centran en una aplicación o innovación, sino en el producto de una IA generativa, casi siempre como notas de color o que buscan el clickbait. Si bien no es mayoritario, este conjunto es de interés porque probablemente contribuya a una naturalización de la IA y, eventualmente, a una disminución de los temores y ansiedades que podría generar. Después de todo, ¿qué temores pueden causar las imágenes de Maradona si las pintaran grandes artistas (Página/12, 28/12/22) o la predicción de la IA de una universidad alemana sobre el final de Game of Thrones? (Clarín, 11/04/19). En otro registro, Pentzold et al. (2019) realizan una observación que puede ponerse en relación con este aspecto de la presente investigación, ya que consignan que en su caso “el hallazgo más interesante parece ser que, de hecho, la mayoría de las imágenes asumen una posición neutral hacia el big data” (p. 163).
La última pregunta de esta investigación (“¿Qué grado de similitud o diferencia existe en el tratamiento de la IA entre los distintos medios considerados?”) se concentra en el nivel de consonancia del tratamiento del tema en los medios analizados. Entre las similitudes generales cabe consignar el tratamiento optimista del tema, con medias en el análisis de sentimiento (scores mayores a 0.7) que van de 3.58 a 4.76 pero con medianas que en todos los casos son del valor más alto (más optimista) de la escala. También es llamativa la altísima correlación en los términos utilizados: es legítimo presuponer que diferentes puntos de vista exigen vocabularios también diferentes, y no es el caso. Otras cuestiones comunes son el predominio de Estados Unidos como la región geográfica en la que se originan la mayor parte de las noticias publicadas y el hecho de que las expectativas son más habituales que los temores.
En otros aspectos parece posible distinguir dos grupos de medios, los “migrantes” y los “nativos” digitales. En los primeros hay una mayor tendencia a la producción propia y esto se relaciona con que el área social de que tratan más habitualmente sea “Economía y empresas”. En el segundo grupo el porcentaje más alto es el de los artículos de los cuales no se puede identificar el origen de su producción y el área social predominante es “Entretenimiento y ocio”. Si bien las notas de color y pasatistas están presentes en todos los medios analizados, es razonable suponer que la lógica del clickbait es más fuerte en los medios nativos digitales.
Conclusiones
En este trabajo se presentan los resultados de una primera indagación exploratoria sobre el tratamiento que los medios digitales generalistas argentinos realizan de la IA y la automatización, a partir de técnicas de procesamiento de lenguaje natural y análisis de contenido cuantitativo. Se ha encontrado que ese tratamiento es mayormente favorable y que predominan las noticias originadas en el primer mundo (Estados Unidos y Europa), con participación minoritaria de las argentinas, especialmente cuando se trata de producciones propias del medio. Hay un predominio de un enfoque empresarial del tema y las voces más citadas para hablar al respecto son los empresarios y, en menor medida, los académicos y científicos. Finalmente, a despecho de sus diferencias en otro orden, los cinco medios estudiados presentan tratamientos muy similares de esta temática, tanto en los términos que utilizan para hablar del tema, fuentes, ámbito geográfico preferente de las noticias, etcétera, y aun cuando diferencias menores permiten distinguir entre dos grupos: aquellos que provienen de ediciones originales en papel (“migrantes digitales”) y aquellos cuya historia es enteramente digital (“nativos”).
Hay varias limitaciones en este estudio. En primer lugar, al limitarse a dispositivos cuantitativos, un análisis más sutil de las operaciones de enmarcado y una indagación de las operaciones retóricas que se utilizan para presentar el tema quedan fuera de alcance. Próximas investigaciones podrían abrevar en dispositivos cualitativos, atendiendo a los beneficios de los enfoques combinados. En segundo lugar, el corpus se limitó a un conjunto de medios publicados en Argentina. Si bien este aspecto constituye una contribución a un área en la cual vienen predominando los análisis realizados sobre medios de Estados Unidos y Europa Occidental, sus límites geográficos son evidentes.
Las tecnologías de IA y automatización revisten una enorme importancia en términos de las transformaciones económicas, laborales, culturales, educativas y sociales que ya están promoviendo, y que sin duda se profundizarán en el futuro próximo. Sin embargo, la tónica general de su tratamiento en los medios analizados no parece ser congruente con dicha importancia. Aun a sabiendas de la complejidad del tema, es necesario insistir en la necesidad de profundizar la capacitación de los periodistas en temas como la alfabetización crítica de datos. Justamente porque nuestra visión no abreva en una posición determinista y, por lo tanto, estamos convencidos de la capacidad de agencia de los sujetos en la definición de las tecnologías, entendemos que una ciudadanía informada y un debate público vivo resultan cruciales. Los medios de comunicación informativos son herramientas centrales para lograr estos objetivos y el estudio de la cobertura que realizan puede alentar, y esa es nuestra expectativa, procesos de mejoría de su calidad.

